
なぜ「Fin」は高性能なのか? ― Fin AI Engineが支える“安全・正確・高速”なAI対応の仕組み ―
AIチャットボットや生成AIを導入する企業が増える中で、
「本当に業務で安心して使えるのか?」という疑問を持つ方も多いのではないでしょうか。
Fin AI Agentは、単なる生成AIではありません。
カスタマーサポート業務で“実運用できる”ことを前提に設計されたAIです。
本記事では、Finが高性能である根拠を、仕組みからわかりやすく解説します。
1. Finは「生成AI」ではなく、CS特化型AIエージェント
Finは以下の構造で成り立っています。
・Fin社独自のAI Engine
・カスタマーサポート向けに最適化された自社LLM
・OpenAIやAnthropicなどの第三者LLM
・専用モデル群
これらを統合し、単なる文章生成ではなく、顧客対応に特化したAI体験を実現しています。
多くのAIエージェントは「LLMへのラッパー」に過ぎず、入出力の最適化ができていません。
Finはその先に進み、高い解決率と低いハルシネーション率の両立を唯一実現しています。
参照:Fin AI Engine™ — Intercom公式ドキュメント
2. Finの精度を支える3つの基盤
Finの性能は、主に以下の3つで構成されています。
① LLM(大規模言語モデル)
問い合わせ内容を理解・最適化し、CS対応に特化した文章理解・生成を行います。
② RAG(検索拡張生成)
FAQやヘルプ記事、外部連携先などから関連情報を検索し、事実に基づいた回答を生成します。
FinのRAGは独自設計(ベスポーク)であり、継続的に精度検証・改善が行われています。
③ Fin AI Engine
生成された回答をさらに制御・検証する独自エンジンです。
「高い解決率」と「低いハルシネーション率」の両立を実現する核心技術です。
参照:Fin AI Engine™ — Intercom公式ドキュメント
3. Finが実現する「安全性・正確性・スピード」
Finは以下の3要素をバランスよく実現しています。
■ 安全性
・不適切なリクエストをブロック
・機密情報を検知しエスカレーション
・コンプライアンスを担保
・OWASP LLM Top 10に対応したセキュリティ対策実施
■ 正確性
・顧客の意図を明確化
・二重チェック機構でハルシネーションを抑制
・曖昧な回答を回避
■ スピード
・最適化されたモデル構成
・キャッシュ活用による高速応答
「速いけど不正確」でも「正確だけど遅い」でもない。
実務に耐えうるバランス設計がFinの特徴です。
参照:Fin AI Security — trust.intercom.com
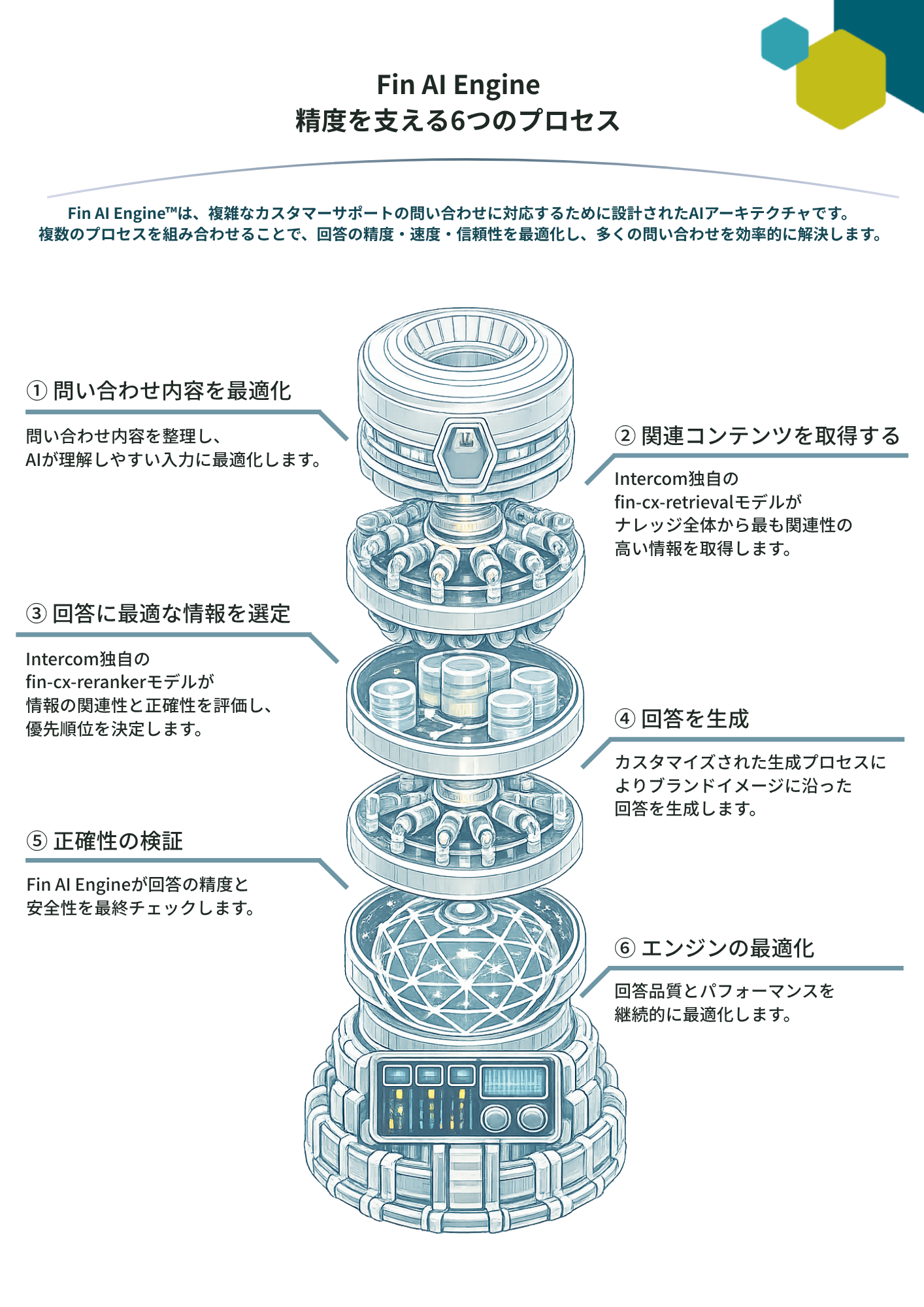
4. 精度を高める6つのプロセス
Finは回答を生成するまでに、6段階のプロセスを経ています。
① 問い合わせ内容を最適化
不適切・機密情報をブロックし、問い合わせ内容を最適化。
② 関連コンテンツを取得する
全ナレッジから最適な情報を抽出。
③ 回答に最適な情報を選定
「新しさ」「信頼性」「実用性」で優先順位を決定。
④ 回答生成
ブランドガイダンスに沿った回答を生成。
⑤ 正確性の検証
回答が適切かどうかを再チェック。
⑥ エンジンの最適化
レポートをもとに改善・チューニング。
このように、単発生成ではなく、設計されたプロセス型AIであることがわかります。
参照:The Fin AI Engine™ — fin.ai/ai-engine / Fin AI Engine™ — Intercom公式ドキュメント
5. Finは「導入して終わり」ではない
Finは使いながら育てていくAIです。
・ナレッジの追加
・ガイダンス調整
・レポートを活用した改善
継続的なチューニングにより、自動解決率や回答精度を高めていきます。
6. まとめ:Finが高性能である理由
Finが高性能と言えるのは、
・ 独自AIエンジンと複数LLMの統合設計
・ RAGによる事実ベース回答
・ 二重チェック機構による安全性確保
・ 継続的最適化設計
・ CS特化型アーキテクチャ
という構造そのものに根拠があるからです。
単なるAIチャットボットではなく、「カスタマーサポート業務を最適化するためのAI基盤」
それが、Fin AI Engineの本質です。
無料でFinの活用方法を相談する
